Things have been quite busy over the last year or so, when I last posted. My wife and I moved to Zurich with our 4-month old, I helped organize a workshop on word order here at UZH, a proceedings volume from the last ICAAL that I co-edited got published in December, we attended a bunch of conferences (AAS in Denver, SEALS in Tokyo, ICHL in Canberra), I lost my passport on the way to ICAAL in Chiang Mai (I’ve since applied for another), and various other things happened.
In the meantime we have also been hard at work digitizing, transcribing, and annotating data from multiple Austroasiatic languages. Alongside this effort we have been developing semi-automated ways of comparing clauses and identifying possible correspondences for syntactic reconstruction. The field of syntactic reconstruction has been gaining traction over the past decade as a viable area for study in historical linguistics (see here, here, and here for some work), and it’s exciting to be working on ways that computers can help us in this task.
One interesting observation we can make is that our methodology does actually identify crosslinguistic structural similarities. We can see this in the following plot, which compares the number of clauses deemed ‘similar’ by our method in two datasets (thanks to Damian Blasi for suggesting this means of assessing our method). The first dataset is our current dataset with over 9,000 clauses annotated. Across 10 languages in 5 subgroups, this results in over 23 million pairwise comparisons. The second dataset is composed of the same clauses, but with the elements in each clause randomized by language. The plotted lines are the distribution of similarity judgments across each dataset.
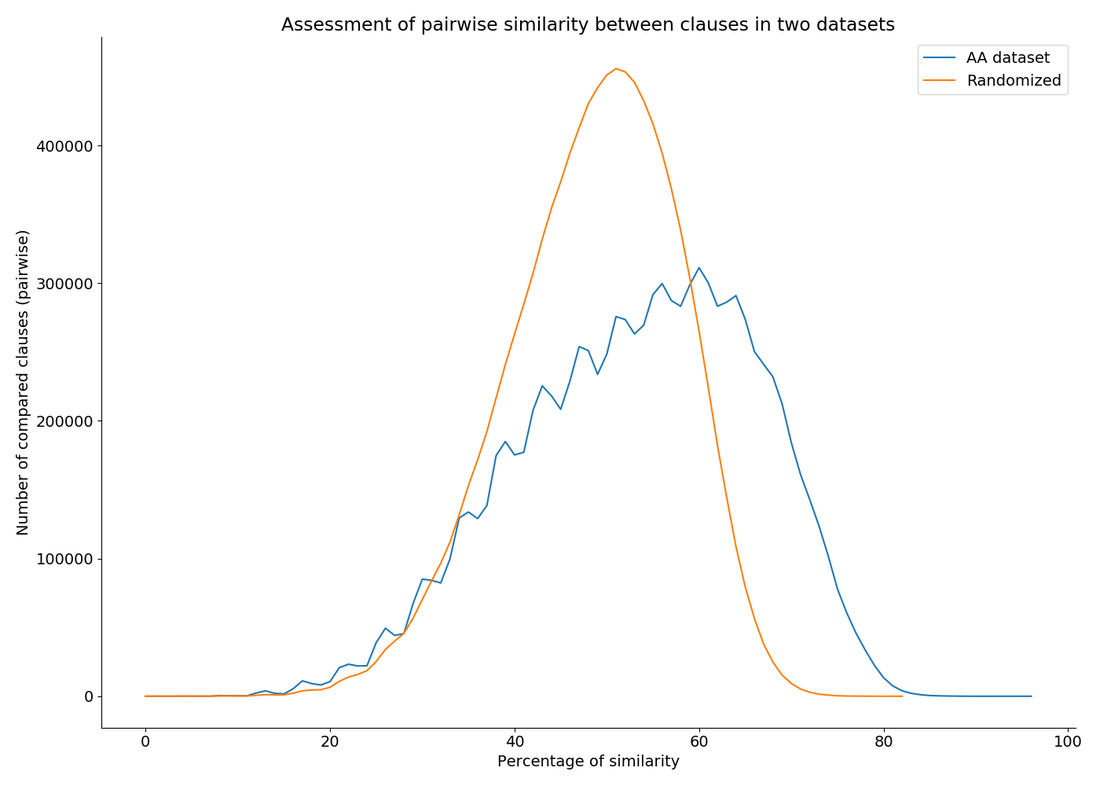
We can see that using our method for clause comparison the randomized dataset shows a normal distribution - which is what we expect from unstructured data. With the same method, however, the dataset of annotated clauses in Austroasiatic languages shows a non-normal distribution. This tells us that the real language data is structured AND that our method for measuring similarity picks up on this structure, identifying a higher degree of similarity between clauses in languages that we know are related.
This raises a lot of new questions and highlights the need for more testing to identify the best way of assessing similarity between clauses in a systematic and linguistically appropriate manner. Fortunately our project is not yet over!